Go 语法速通
以下为学习B站大地Go课程Go语言基础部分的的笔记输出,作为平时查阅的资料,希望也可以帮助读者快速熟悉Go语言
经典Hello World
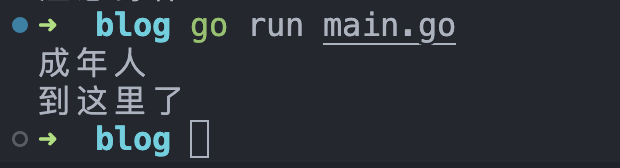
首先是经典的输出Hello World,Go语言的fmt包中包含了输出函数Print、Println、Printf,如下代码输出Hello World
|
|
使用go run main.go来执行该go文件,输出Hello World。
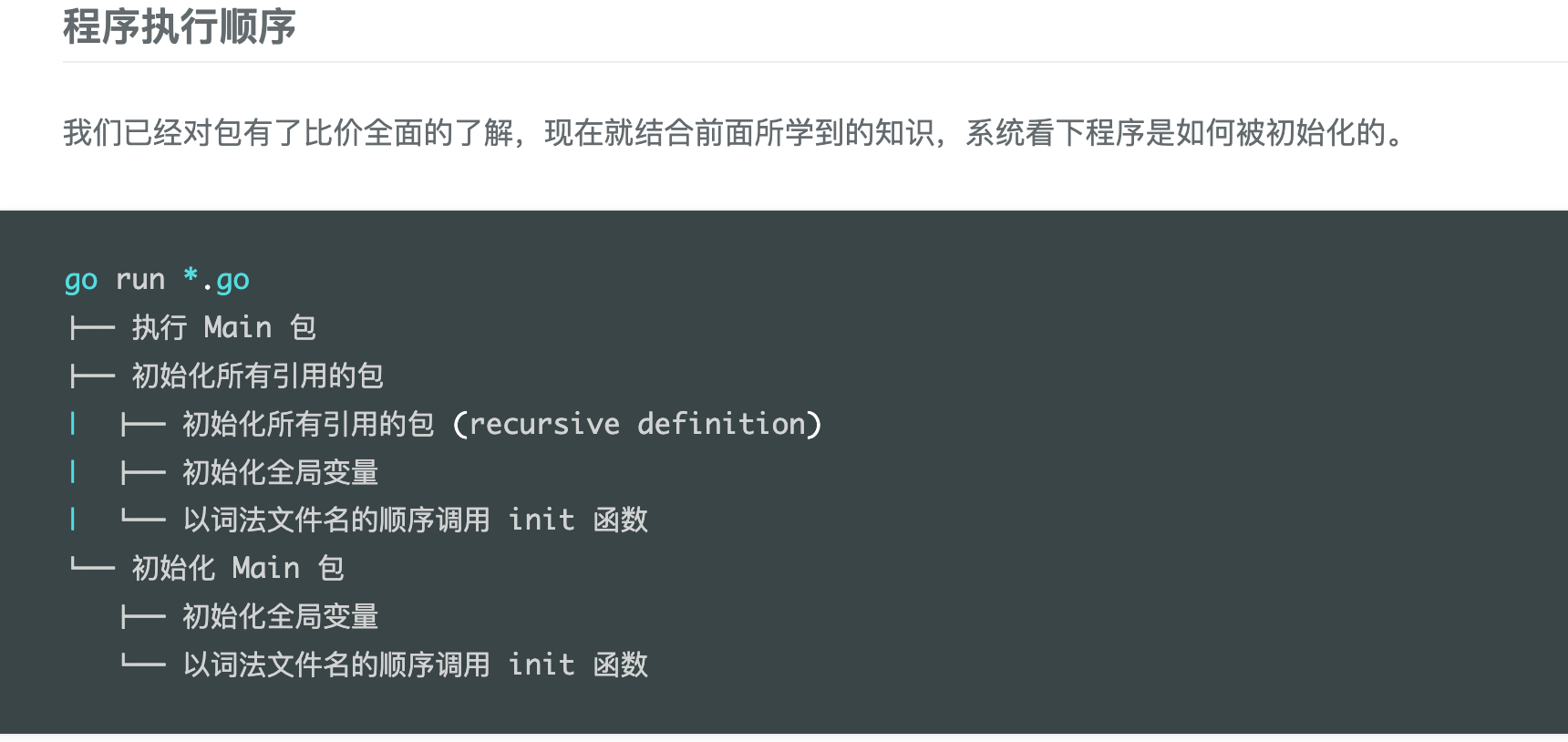
这里补充一个go程序执行的顺序
知识点
-
package标识了go文件所属的包,在go中只有main函数,且main函数所处的包必须是main包,包中的元素(函数、变量)通过大小写来确定其访问权限,具体细节可以参考 Go 语言包管理(Package)必知必会 彻底理解 Go 的包概念 Go语言中的包和库:一次全面的理解 理解Go语言包(package) go module 与 package
-
fmt包是Go的标准库之一,其有很多强大的功能具体可以参考 深入理解 fmt 包 golang fmt格式“占位符”
Go 变量 常量 与 命名规则
命名规则
Go语言的变量命名规则和大多数的语言是一样的,以数字字母或者下划线且首字母不能为数字都可以定义为变量名,但是不可以使用关键字作为变量名。具体的规则如下
- 变量名必须有数字、字母下划线组成
- 标识符开头不能为数字
- 标识符不能是保留字和关键字
- 变量的名字是区分大小写的
- 标识符一定要见名思意,变量名称建议使用名词,方法名建议使用动词
- 变量命名一般采用驼峰式,当遇到特有名词如DNS等的时候,特有名词根据是否私有全部大写或者小写(变量的公有还是私有根据变量名的大小写来决定)
- 常量变量也可以使用
_作为开头
代码风格
- 代码每一行结束后不写分号
- 运算符左右建议加一个空格
- 推荐使用驼峰命名
- 左括号不分行如if { 在一行
- if 判断条件的() 不用写 不同于其他语言
变量
使用var定义变量,在Go中定义完变量后必须去使用,使用var声明后不对其进行赋值的化该变量值为空(其对应类型的空值)。
声明初始化变量有两种方式
var 变量名 类型 = 表达式 类型可省略变量名 := 表达式生命并初始化 短变量声明法 只能局部变量
对于第一种声明赋值方式可以看下面的例子
|
|
上面的代码都是为定义username为字符串变量同时为其赋值,可以通过上面的代码看出go的编译器具有类型推导的能力。
go语言中变量需要声明后使用,同时同一作用域内不支持重复声明相同的变量
变量还可以一次定义多个,但是前提是类型必须相同如
|
|
对于类型不一致的变量如果想要一次定义多个的化可以使用如下方法
|
|
短变量声明法
变量名 := 表达式
只能作为局部变量,不能为全局变量
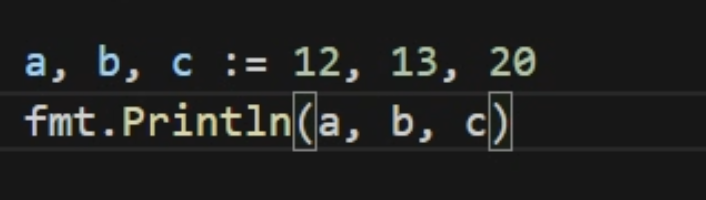
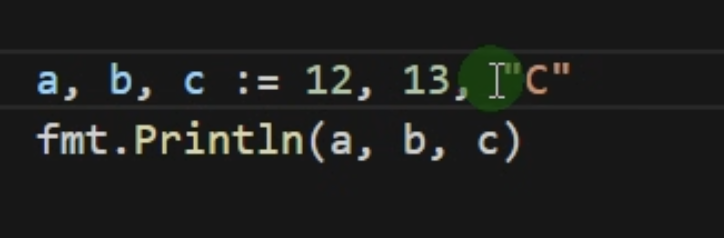
一次声明多个变量并初始化可以声明相同类型与不同类型的变量
匿名变量
匿名变量在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量,匿名变量使用_表示和Swift中使用一样如下所示
|
|
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明
变量使用前必须初始化,声明后必须使用
常量
常量的值是不可以改变的,使用const关键字定义常量,定义常量时必须要赋值如下所示
|
|
多个常量也可以一起声明如
|
|
const 同时声明多个常量的时候,如果只赋值了第一个值则后面的值都是一样的
|
|
iota
iota是go语言中的常量计数器,const中每新增一行常量声明将会使得iota计数一次
iota默认值是0,直接定义iota的值为0
|
|
在一次定义多个const变量的时候,iota初始化为0且会自增
|
|
在iota生命中插队
|
|
iota多个定义到一行
|
|
上面的是由于iota每新增一行定义+1,同时定义了一行中的两数的规则 对应规则很容易推断出每个变量对应的值
数据类型
int类型
整型分为以下两个大类
- 有符号整型按照长度分为 int8 int16 int32 int64
- 无符号整型 uint8 uint16 uint32 uint64
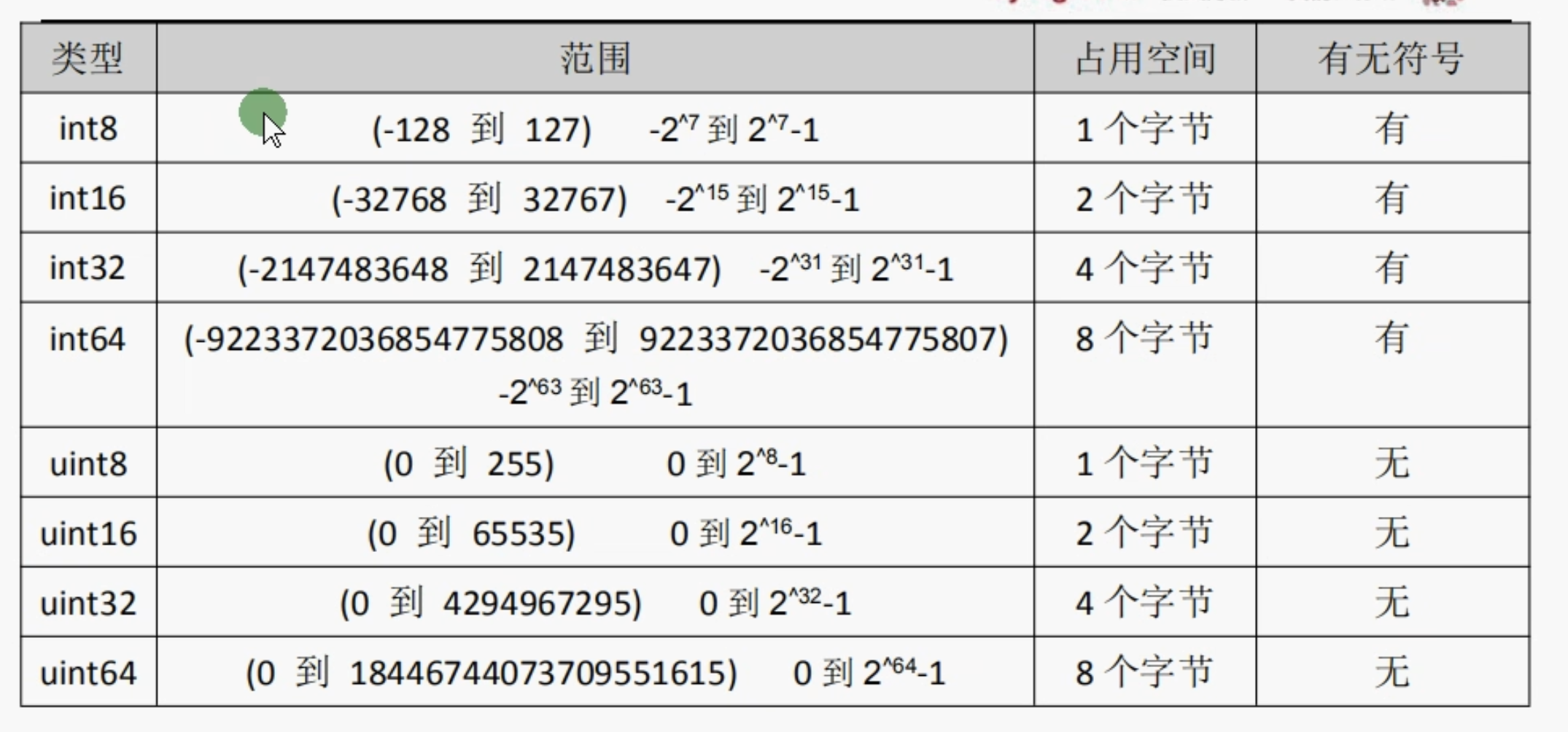
使用unsafe.Sizeof可以查看不同长度的整型 在内存中占用的存储空间 单位是字节数 补充:
|
|
整型类型转化
|
|

在强转的时候要注意高位向低位转化的时候的溢出问题 int 属于简写目的是为了兼容 在64位系统上其为int64 在32位系统上其为int32
字面量输出语法
|
|
float浮点型
Go语言支持两种浮点类型,float32和float64,这两种浮点类型数据格式遵循IEEE754标准,float32的浮点数最大范围为3.4e38, 可以使用常量定义math.MaxFloat32,float64的浮点数的最大范围约为1.8e308,可以使用一个常量定义math.MaxFloat64
打印浮点数的时候可以使用fmt包配合%f占位符来打印
为啥浮点类型就没有个float在不同系统上表现为float32与float64
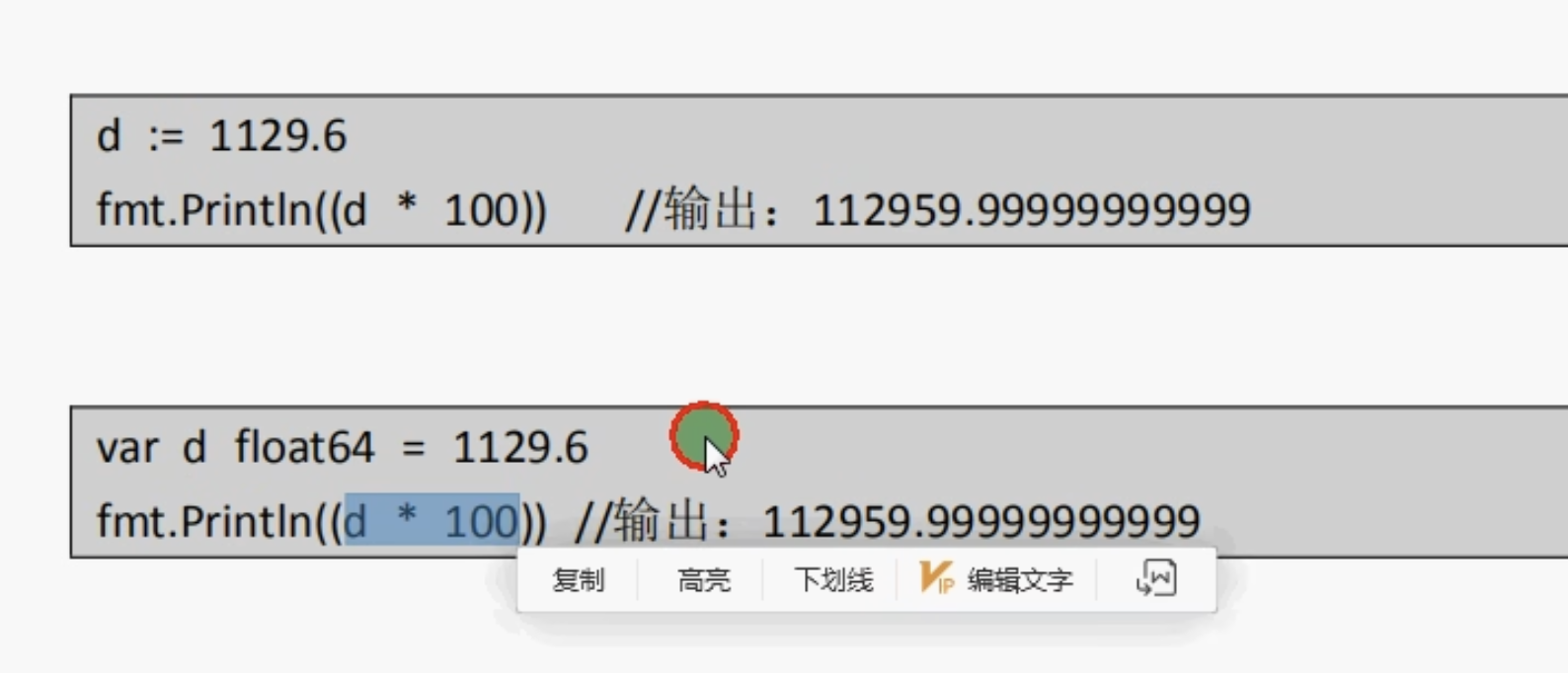
float精度丢失问题
几乎所有的编程语言都有精度丢失这个问题,这是典型的二进制浮点数精度丢失问题,在定长条件下,二进制小数和十进制小数互转可能存在精度丢失


int与float的转化
直接使用类型()来强转,但是高位转化为低位的时候注意溢出的问题,float转化为int的时候直接截取小数部分
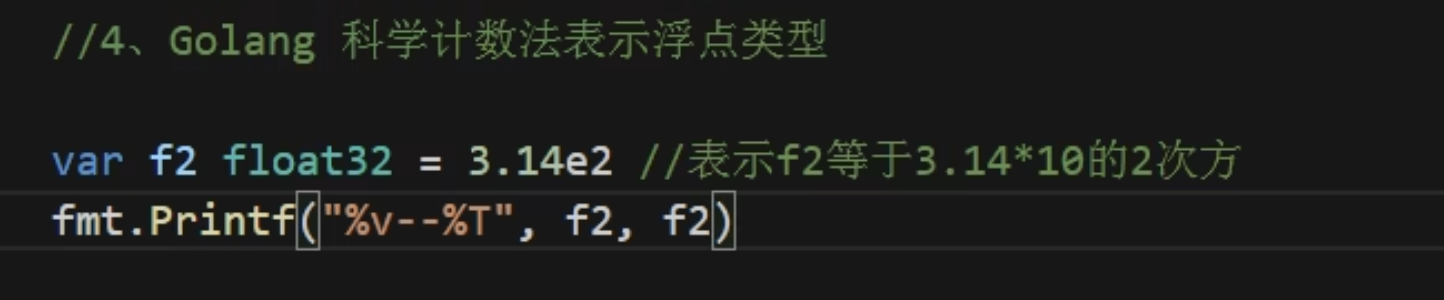
科学计数法

bool类型
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true和false两种值。
- 布尔类型变量的默认值为false
- Go语言中不允许将整型强制转化为布尔类型
- 布尔型无法参与数值运算,也无法与其他类型进行转化
字符串类型
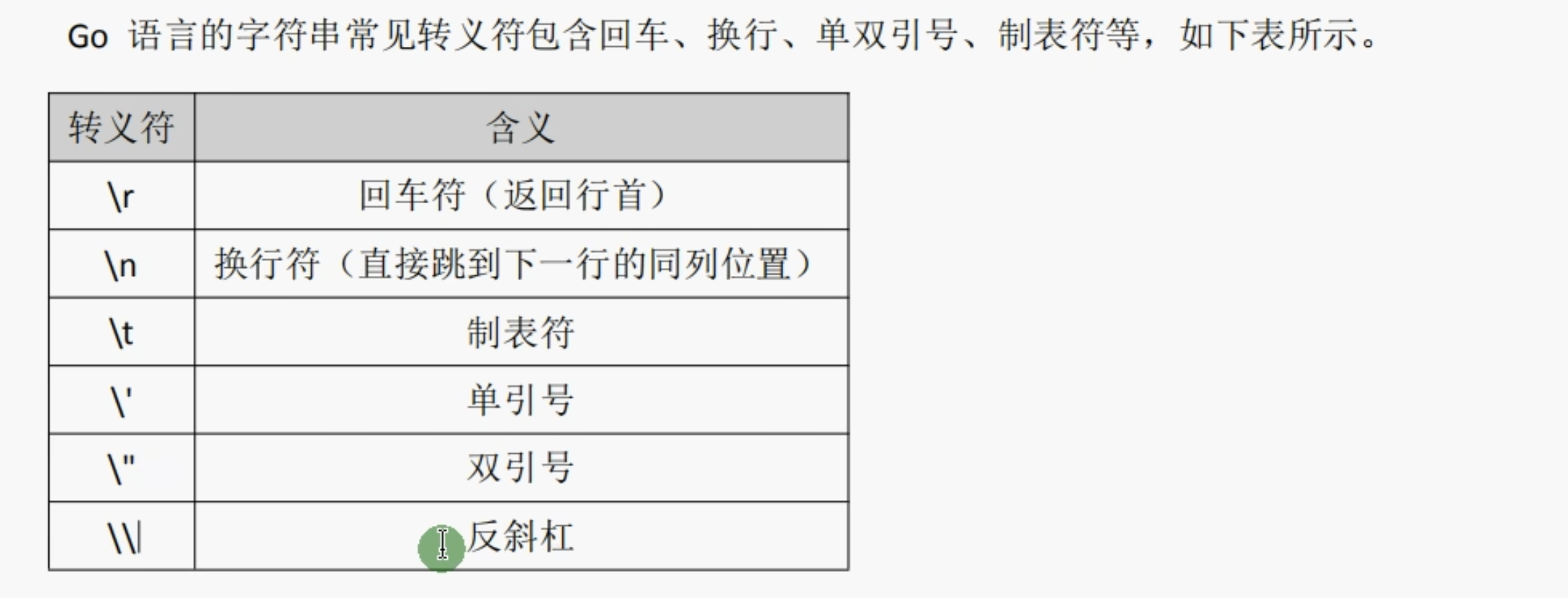
字符串转义
输出多行字符串
和其他语言类似也是使用两个反引号
|
|

字符串常用方法

字符串长度 输出的是字节数 汉字占用四个字节
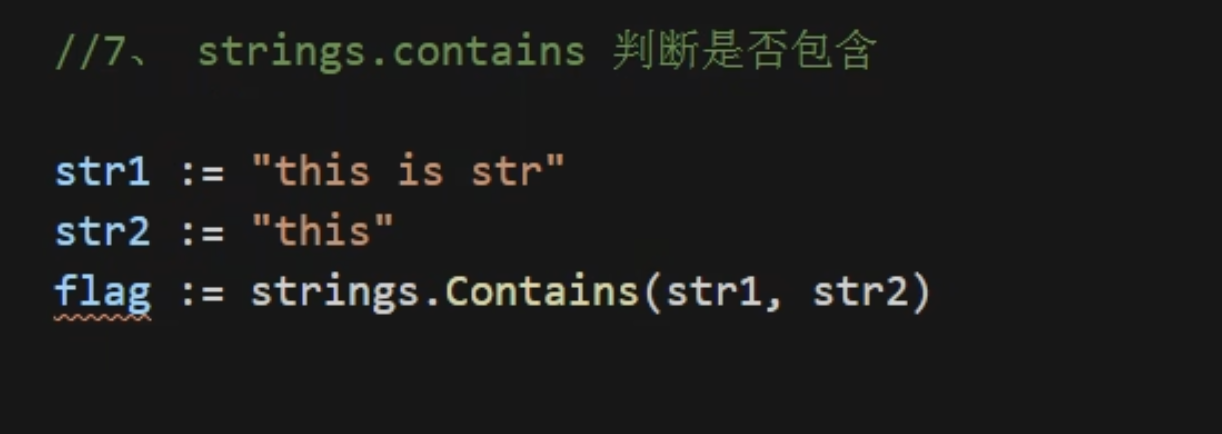
contains 是否包含子串 str2是否包含在str1
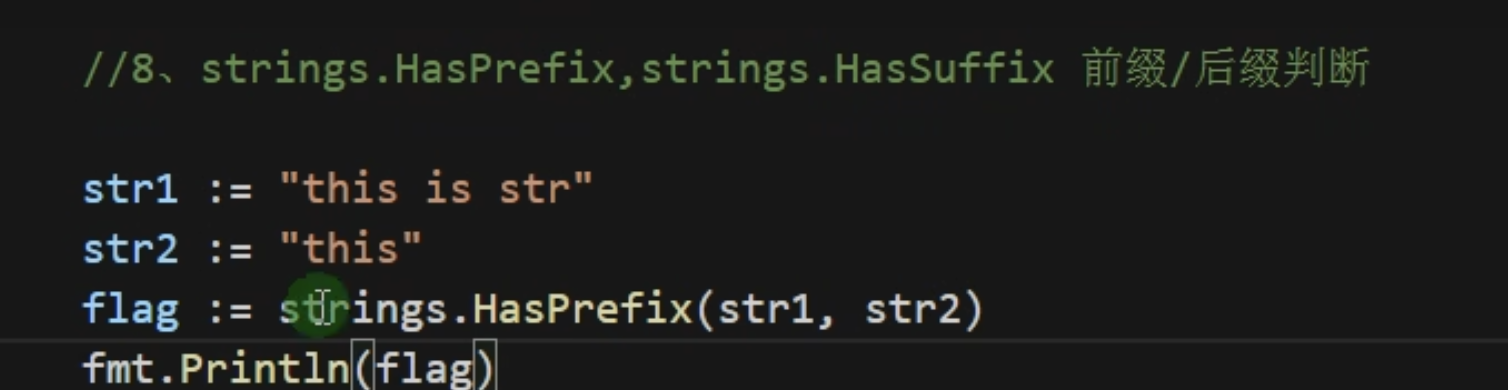
同样的HasPrefix 和 HasSuffix 以及 index lastIndex也一样第一个参数都是全集的字符串 str2为子集
lastIndex表示最后出现的位置 index与lastindex查找不到的话返回-1
byte和rune类型
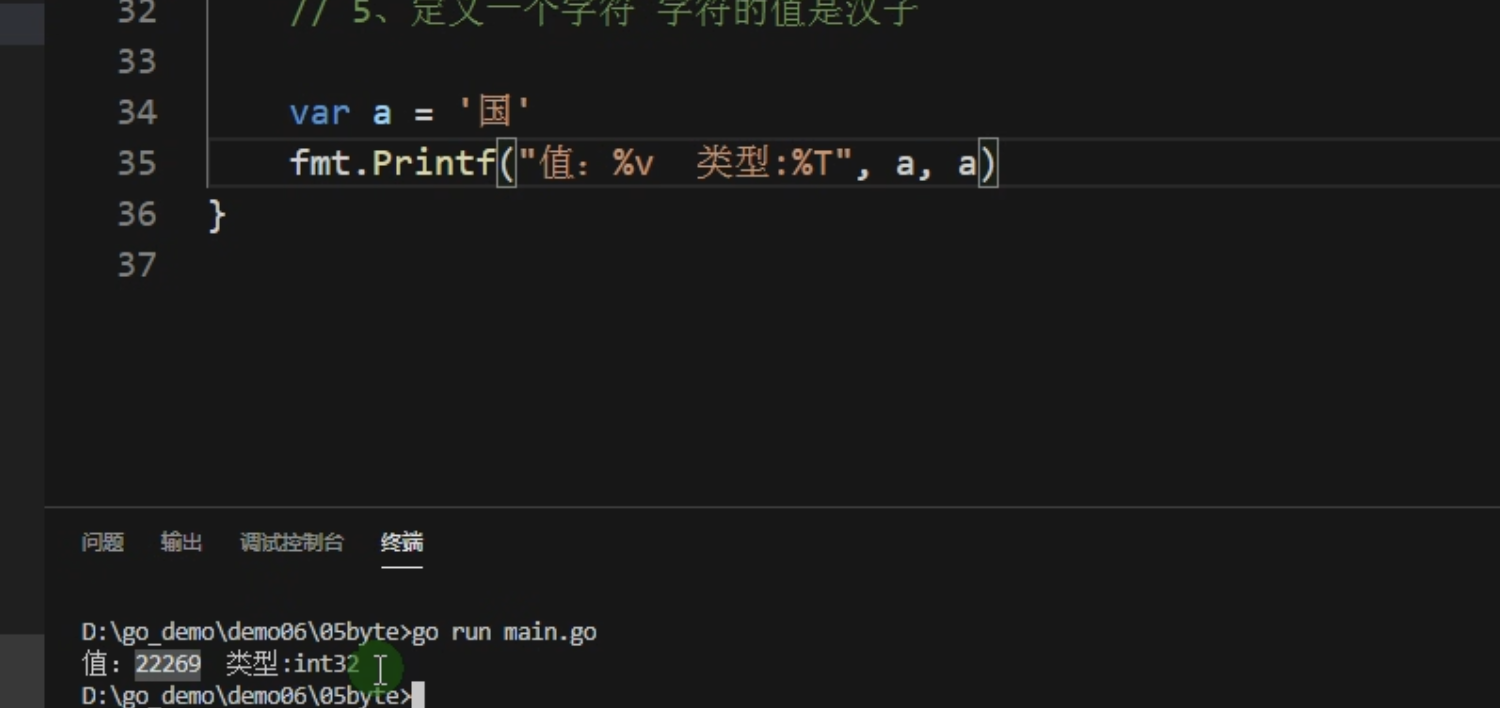
组成每个字符串的元素叫做”字符“,可以通过遍历字符串元素获得字符,字符用单引号包裹起来 Go中的字符属于int类型,默认输出为ASCII码值(使用%v 如果想要原样输出使用%c)

byte 占一个字节 byte -> uint8 rune 占4个字节 rune -> int32
获取字符串中的字符 直接使用下标获取

go中汉字占用四个字节,一个字母占用一个字节 unsafe.sizeOf无法获取字符串占用的大小(获取的是结构体的大小),只能使用len来查看string类型占用的存储空间 但是如果包含了中文的话len的长度并不是字符串的实际长度
打印字符 字符是汉字 类型是int32
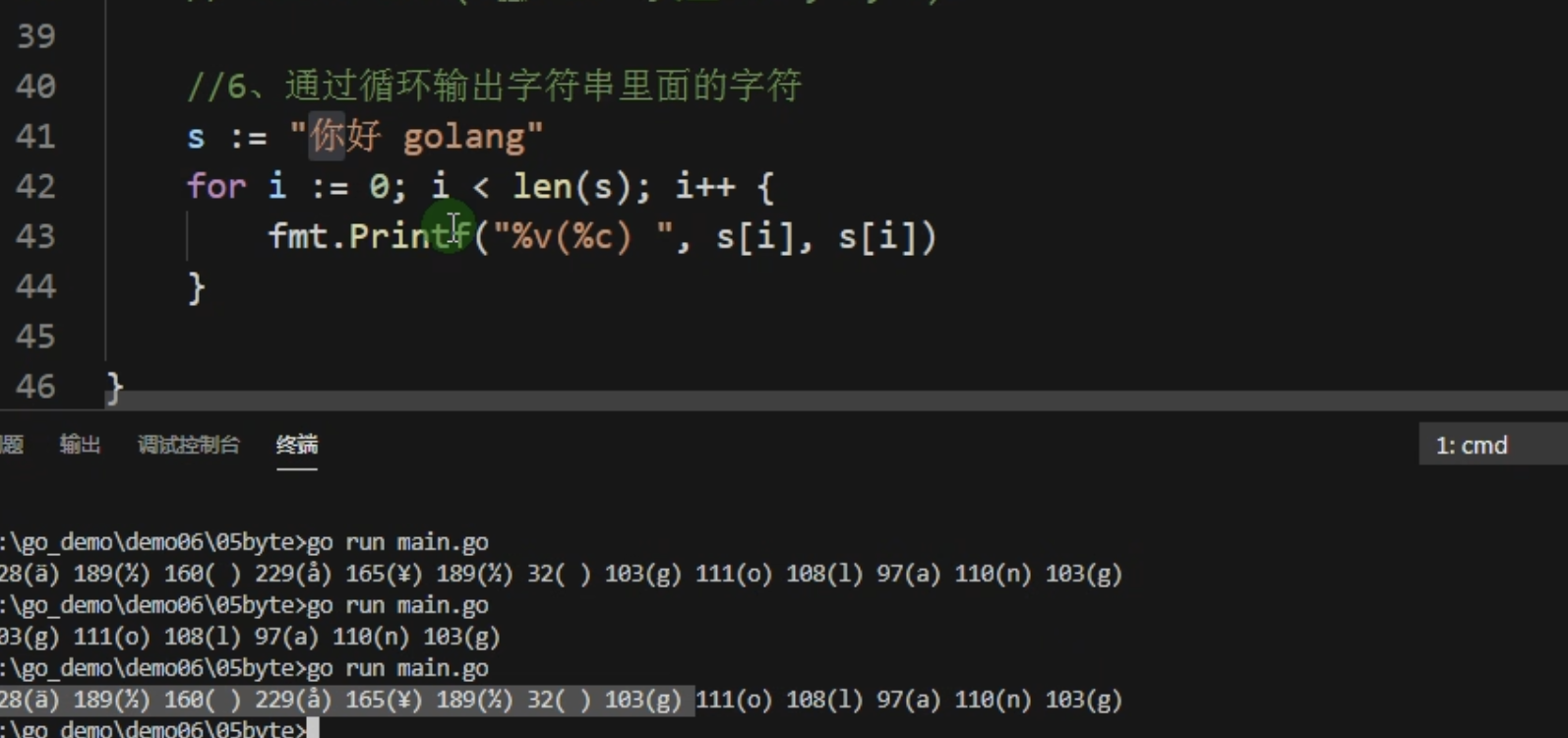
循环字符串里面的字符
包含汉字的使用for循环有问题 汉字占4个字节
使用range循环 表示一个utf8类型
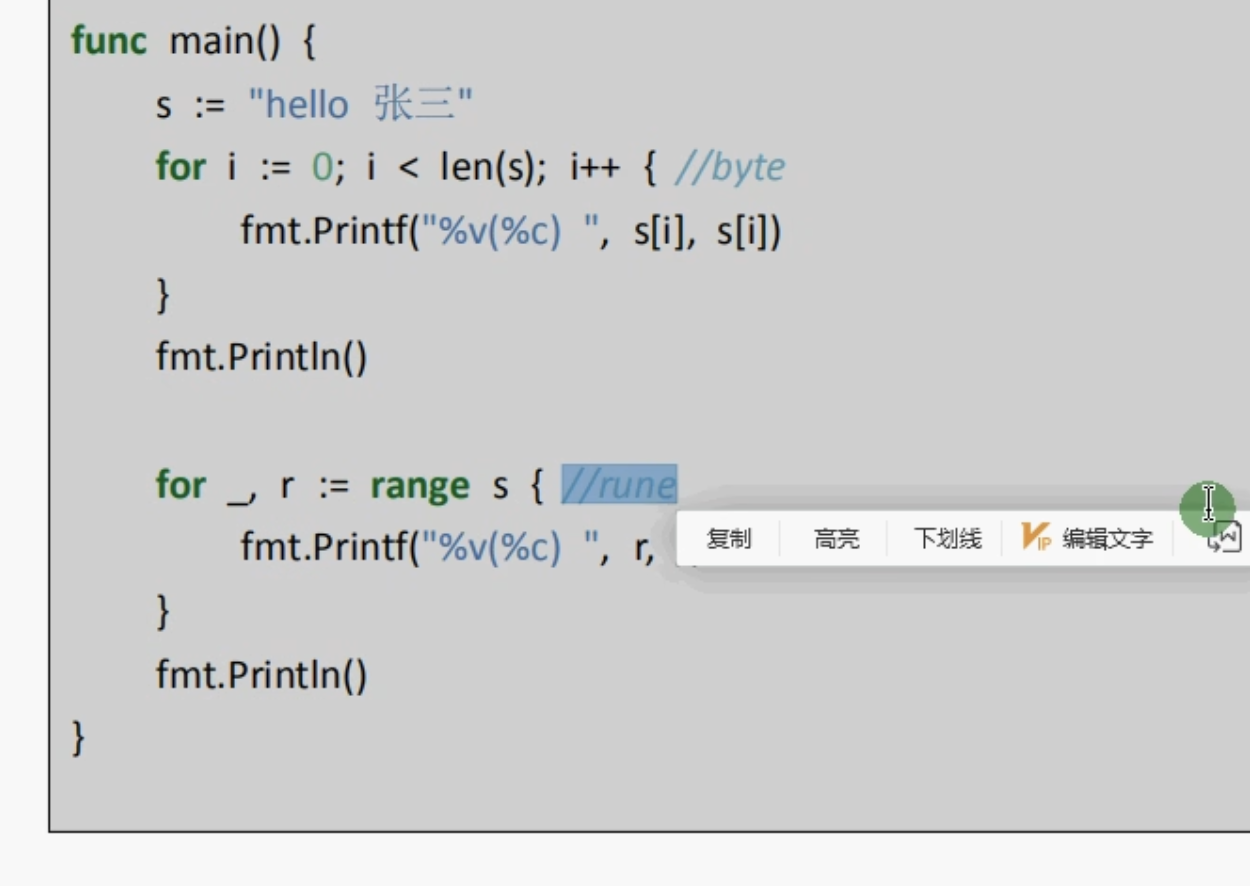
字符串直接使用for的话是使用byte表示一个字符,使用range循环表示使用rune表示一个字符 如果要循环的字符串只有英文字母的话可以使用for循环 不然的应该使用for range循环
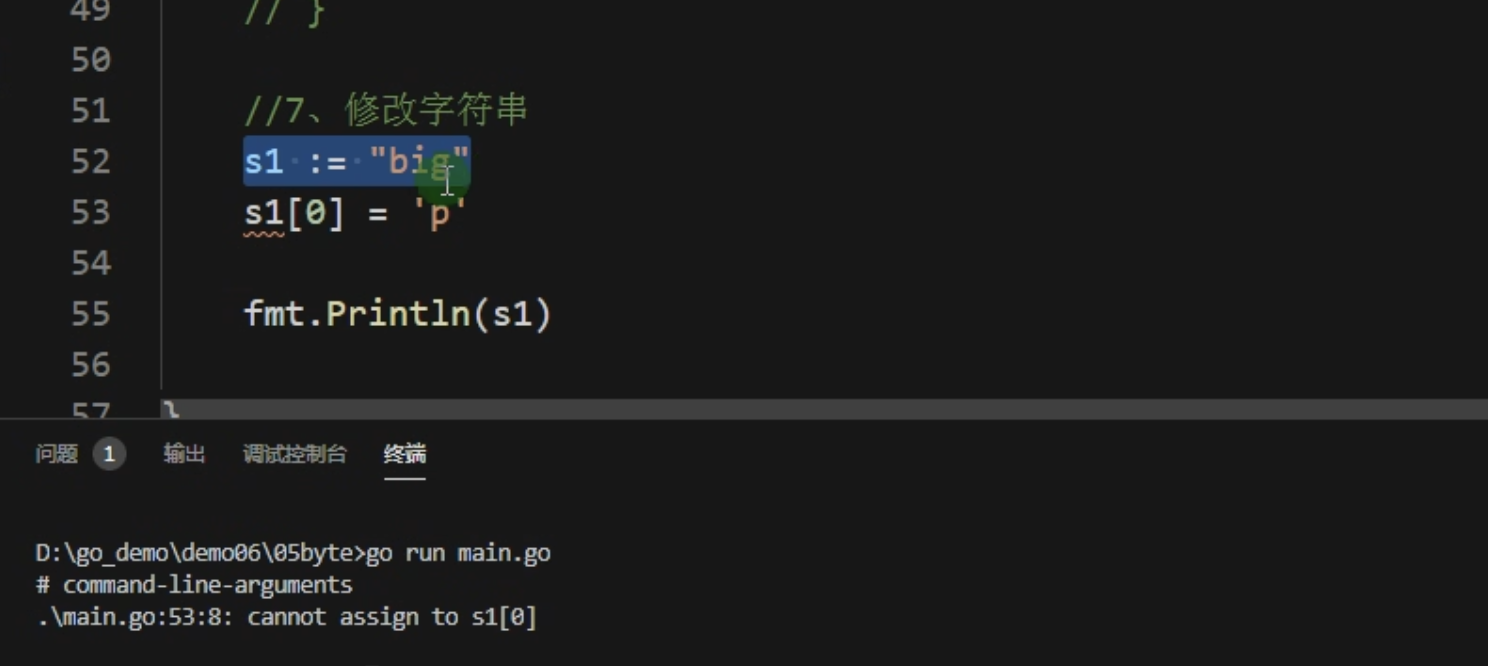
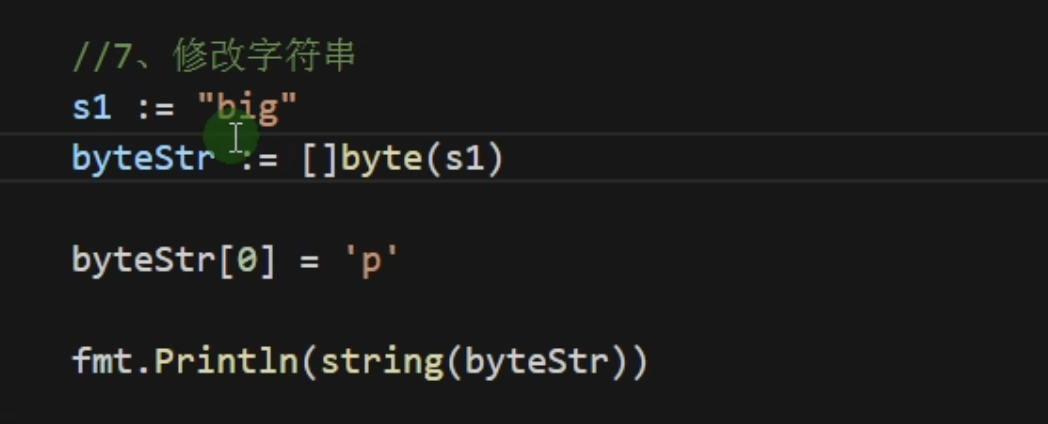
修改字符串
要修改字符串,需要先将其转化为[]rune或者[]byte,完成后在转化为string,无论哪种转化,都会重新分配内存,并复制字节数组
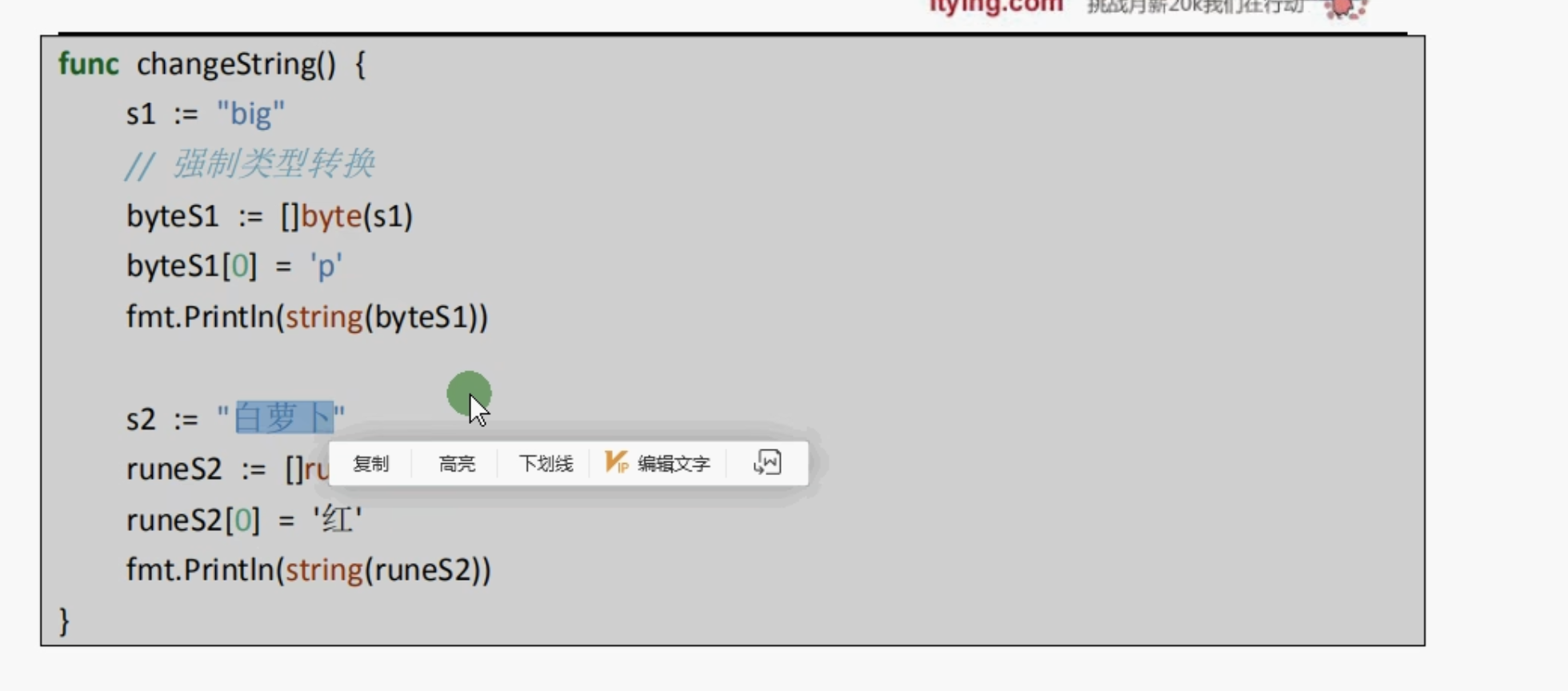
直接赋值的话没法修改字符串的
应该先去转化
至于要转化成哪种数组主要看是否包含除了英文字母以外的其他字符
数据类型
int 整型
|
|
这种数值的转化建议从低位转化为高位, 防止溢出情况的发生
string类型
其他类型转化为string类型
使用fmt包中的Sprintf将其他类型转化为string类型
|
|
使用strconv包来进行类型转化
strconv.FormatInt两个参数
- int64的数值
- 传值int类型的进制
|
|
同理还可以使用strconv.FormatFloat转化
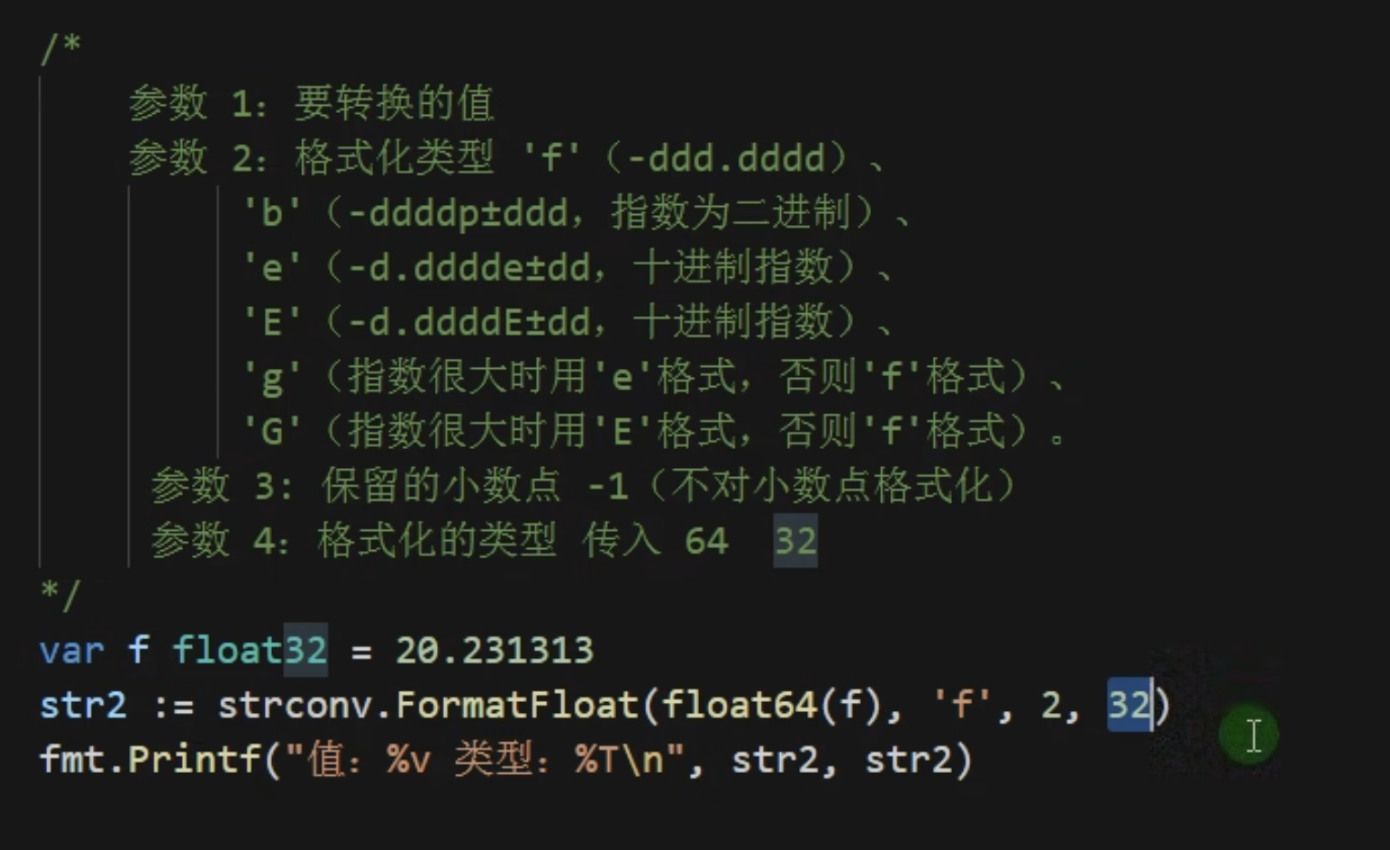
string类型转化为数值类型
使用strconv.ParaseInt转化
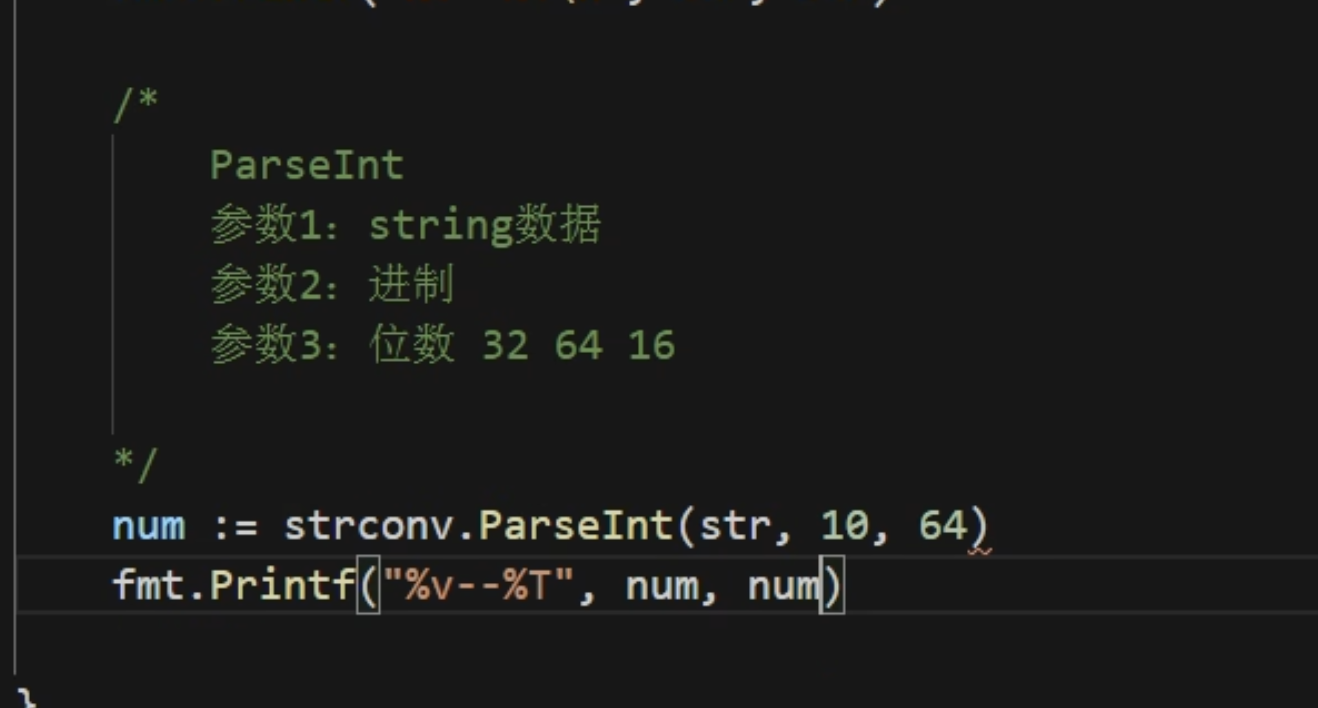 同理可以使用
同理可以使用strconv.ParaseFloat转化
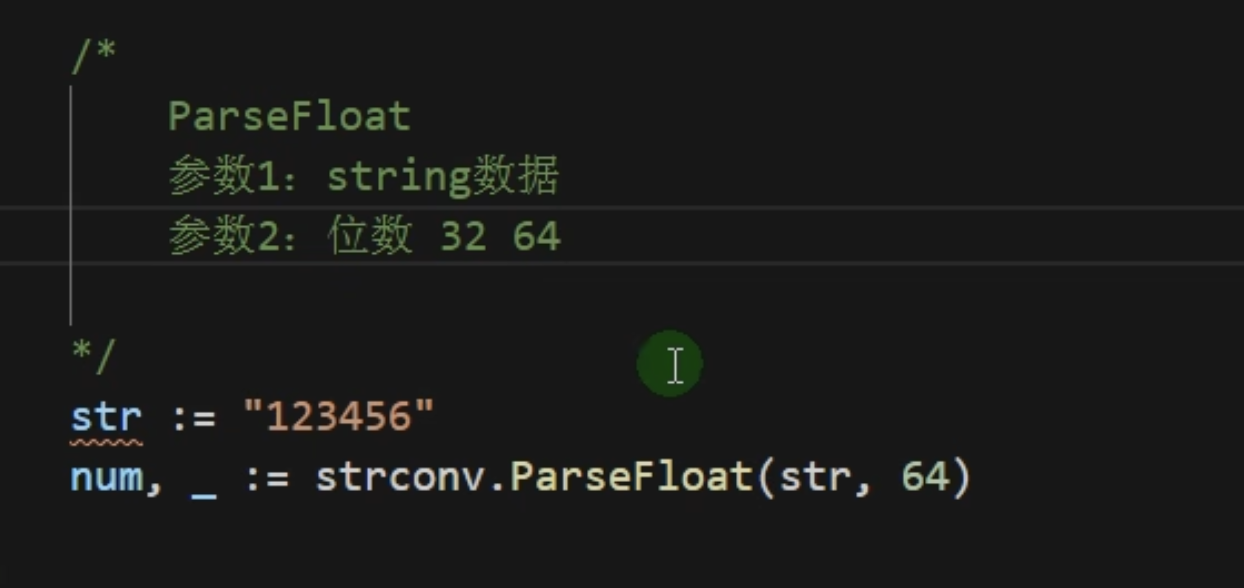
这里补充下使用fmt输出的占位符








其他基本数据类型,如bool float等与其他语言的基础数据类型相似
Go 复合数据类型 - 数组
数组的定义
 数组的定义方式为
数组的定义方式为
var 数组变量名 [元素数量] T
通过%T打印数组的类型可以发现,数组的长度也是属于数组的类型
int类型的数组声明后为初始化其元素值为0,string为空字符串
数组声明为未初始化的时候数组中的元素为对应类型的空值
数组的初始化方式有很多种,下面将一一介绍
- 方式一
|
|
- 方式二
|
|
- 方式三 按照上面的方法每次都要确保提供的初始值和数组长度一致,一般情况下我们可以让编译器根据初始值的个数自行推断数组的长度,例如
|
|
可以自动根据初始化列表的值来初始化数组的长度 使用
len()来查看数组的长度,数组的长度初始化后不可以改变
- 方式四 可以使用指定索引值的方式来初始化数组
|
|
使用指定索引的方式来初始化数组,按照最大下标的值来初始化数组的长度,没有声明的值为对应类型的空值
数组的类型
基本数据类型与数组均为值类型
下面要说到的切片为引用类型
- 值类型,改变副本的值,不会改变本身的值
- 引用类型,改变副本的值,会改变本身的值 本质上是改变引用指向的原本的位置的值
多维数组
多维数组的定义
var 数组变量名 [元素数量][元素数量] T
|
|
同时多维数组的定义还支持通过列表元素的数量推断数组的长度
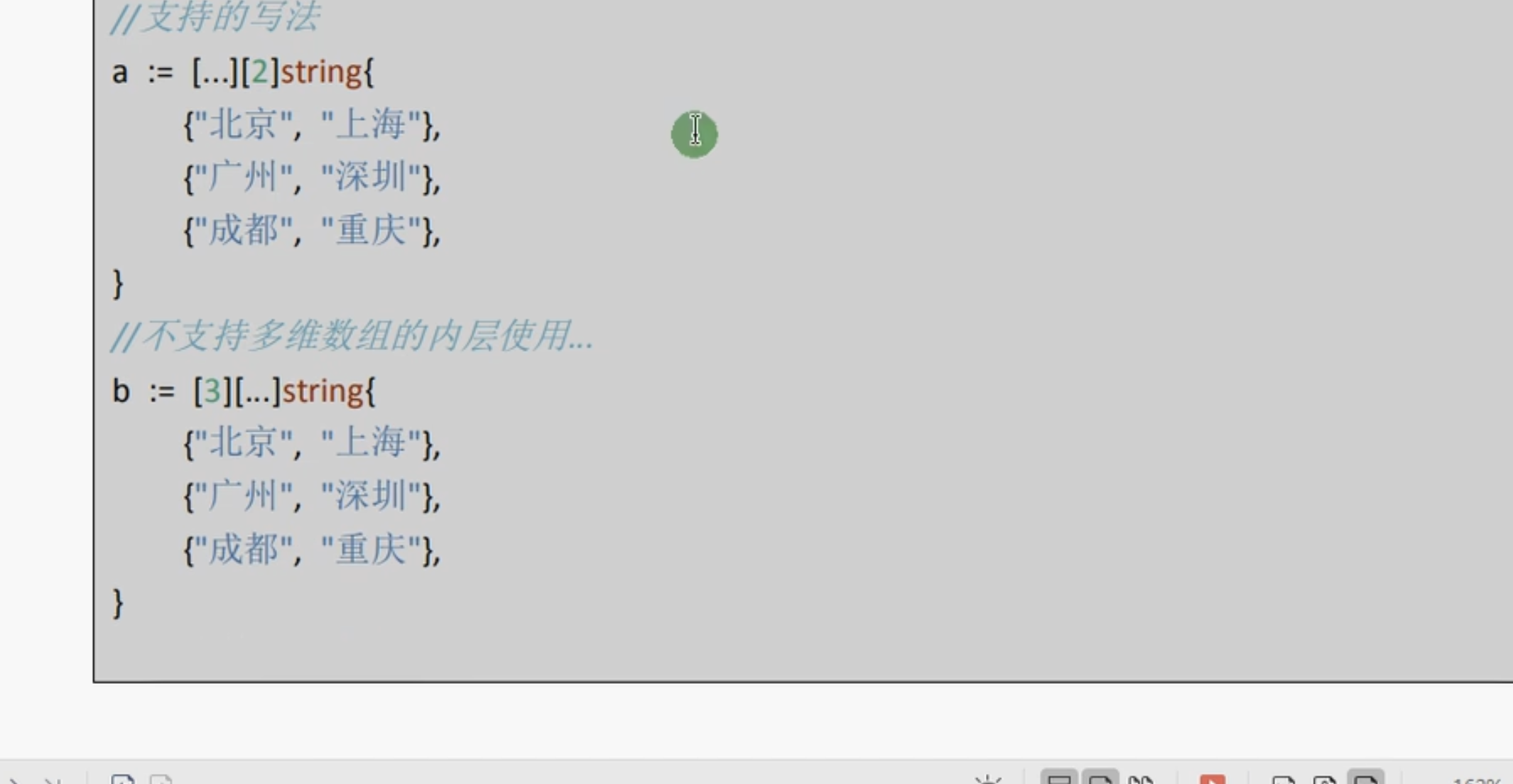
这个种写法仅支持外层(只有第一层)的数组的使用
Go 复合数据类型 - 切片
切片的定义
切片-Slice是一个拥有相同类型元素的可变长度的序列,他是基于数组类型做的一层封装,他十分的灵活可以支持自动扩容,切片是一个引用数据类型,他的内部结构包含了地址、长度和容量
切片的声明如下格式
var name []T
- name 为变量名
- T 表示切片中的元素类型
Slice 拥有相同的类型元素的可变长序列,切片是引用数据类型 与数组定义的区别在于不写长度
声明与初始化
同样的切片也具有多种的声明与初始化方式
- 方式一
|
|
- 方式二
|
|
- 方式三
|
|
切片的默认值是nil

切片的循环遍历
与数组的方式一样
|
|
基于数组定义切片
切片可以从原本存在的数组中定义
|
|
也可以获取数组部分
|
|

基于切片的切片

与基于数组的切片相同
切片的长度和容量
切片拥有自己的长度和容量,可以通过内置的len()函数求长度,使用内置的cap()函数求切片的容量
切片的长度就是它包含的元素个数
切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数
切片s的长度和容量可通过表达式len(s)和cap(s)来获取。

切片的本质
切片的本质就是对于底层数组的封装,他包含了三个信息:底层数组的指针,切片的长度,切片的容量
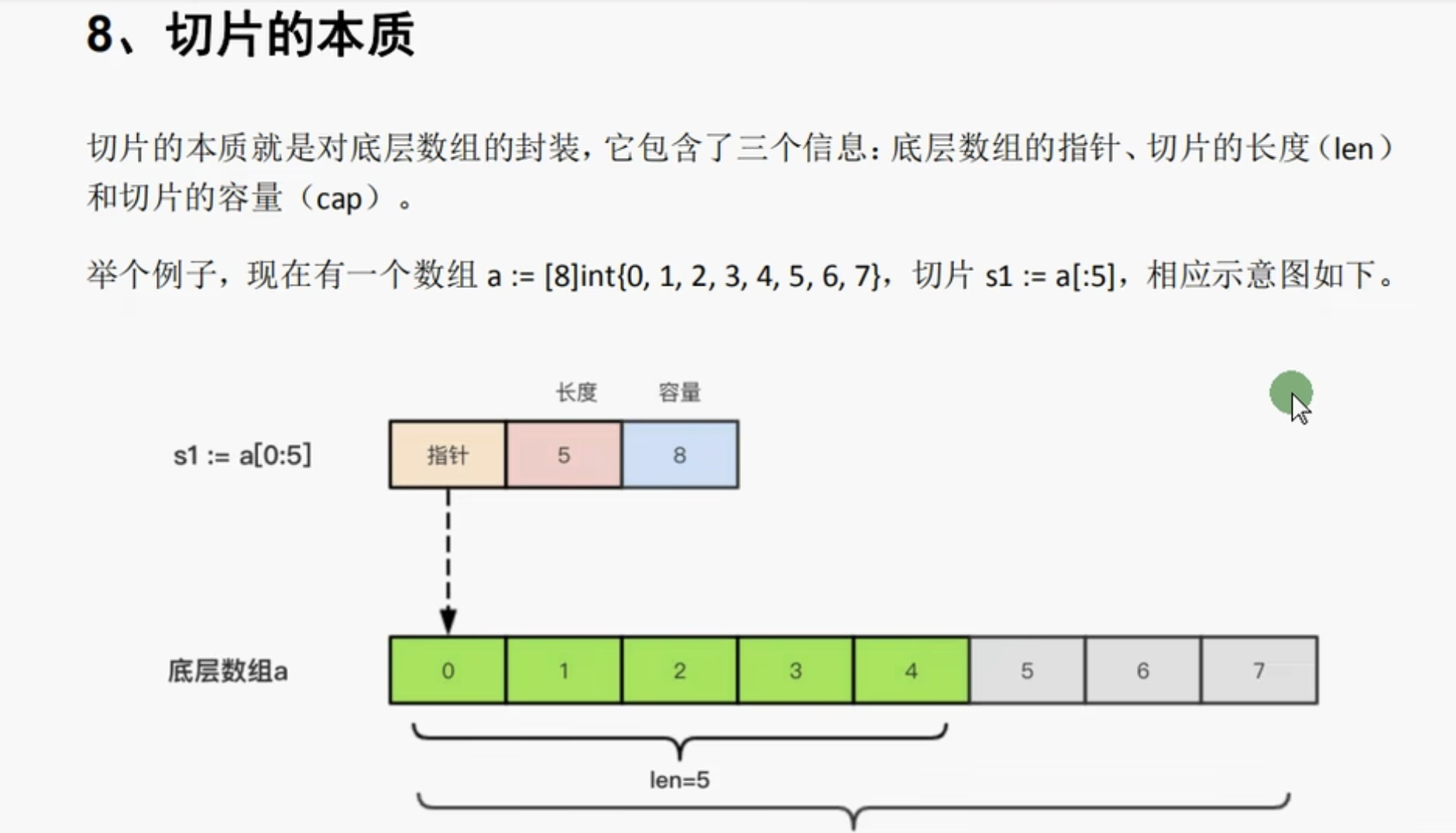
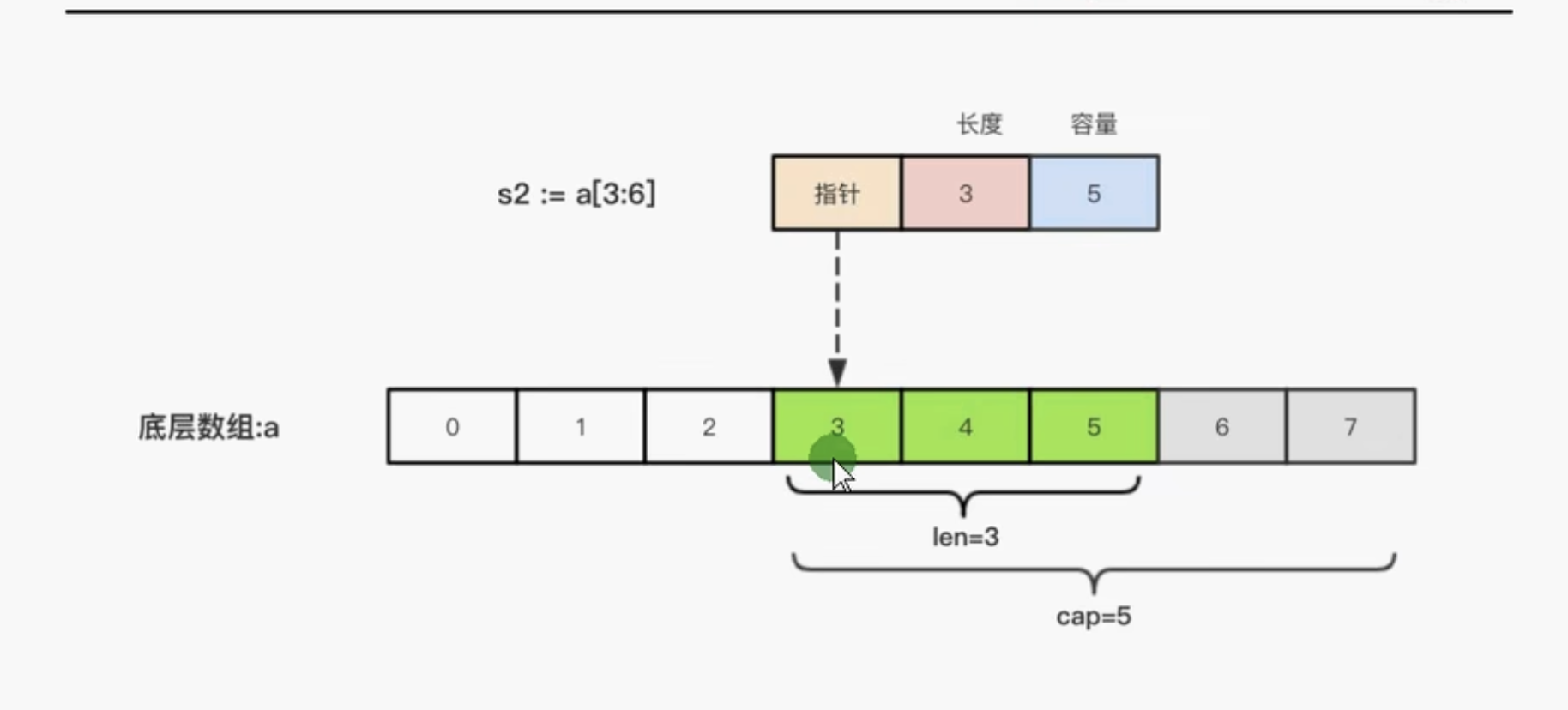
切片本身是数组的封装,指针指向切片的开头,长度为切片的长度,容量为切片开始位置到数组末尾
make() 常见切片
上面对于数组的赋值都是采用既有的数据,如果需要动态的创建一个切片,我们就需要使用make()函数来创建切片具体的格式如下
make([]T, size, cap)
- T 切片的元素类型
- size 切片中元素的数量
- cap 切片的容量
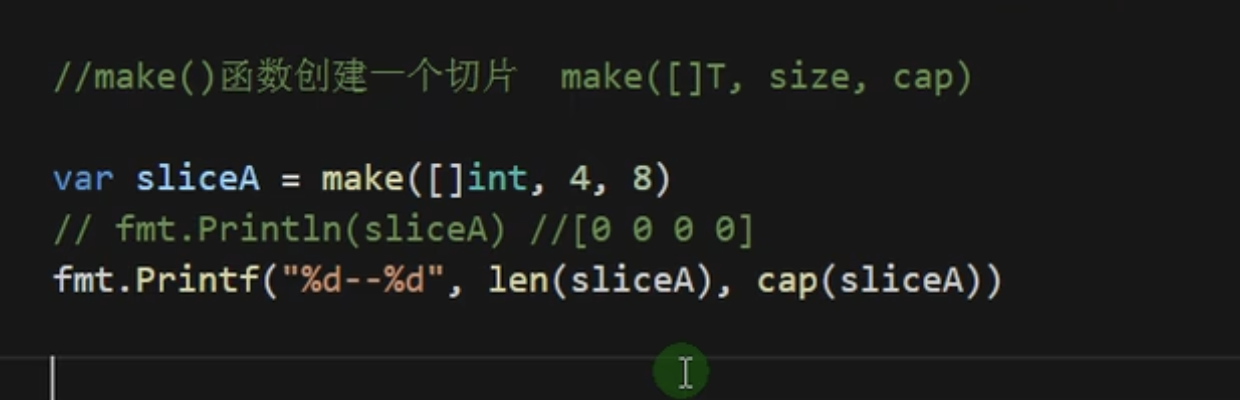 创建的Slice中元素的值为对应类型的零值
创建的Slice中元素的值为对应类型的零值
Append方法的使用
切片扩容
对于切片的扩容需要用到append方法
golang中没法通过下边的方式给切片扩容,指的是直接在arr[x] = 0,x为当前切片的最大长度+1,这样的操作会引起越界错误 使用
append()方法来进行扩容如下
|
|
合并切片
使用append()方法可以将两个切片合成一个切片
|
|
其中...表示拆包,将sliceB中的元素打平
切片的扩容策略
- 首先判断,如果申请容量大于2倍的旧容量,最终容量就是申请的容量
- 否则判断,如果旧切片长度小于1024,则最终容量就是旧容量的两倍
- 否则判断,如果旧切片长度大于等于1024,则最终容量从旧容量开始循环增加原来的1/4,直到最终容量大于等于新申请的容量,即1/4的步长增加
- 如果容量计算值溢出,则最终容量就是新申请容量
需要注意的是,切片扩容还会根据切片中元素的类型不同而做出不同的处理,比如int和string类型的处理方式就是不同的
对应源码的位置在slice扩容策略
使用copy()函数复制切片
make创建sliceB切片,copy拷贝A到B值复制避免引用类型影响 代码如下
|
|
从切片中删除元素
go 语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素
|
|
左包右不包 append合并切片的时候最后添加的切片要加…因为参数类型为element… 其实…操作符表示将元素打开成为单独的element
切片排序算法以及sort算法包
选择排序
|
|
冒泡排序
|
|
sort算法包
对于int float64和string数组或是切片的排序,go分别提供了sort.Ints()、sort.Float64s() 和 sort.Strings()函数,默认都是从小到大排序
|
|
go的sort包也可以使用sort.Reverse(slice)来调换slice.Interface.Less,也就是比较函数,所以int、float64和string的逆序排序函数可这样写
|
|
Go 复合数据类型 - map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用数据类型,必须初始化后才能使用,Go语言中的map定义语法如下
map[KeyType]ValueType
其中
- KeyType: 表示键的类型
- ValueType: 表示键对应的值的类型
map类型的变量默认初始化为nil,需要使用make()函数来分配内存,语法为
maps := make(map[string]string)
make 用于slice map 和 channel的初始化
创建与初始化
make创建
|
|
初始化的时候赋值
|
|
循环遍历
|
|
map类型的CURD
创建map类型的数据
|
|
修改map类型的数据
|
|
获取 查找map类型的数据
|
|
使用delete() 函数删除键值对
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下
delete(map对象, key)
其中
- map 对象表示要删除键值对的map对象
- key 表示要删除的键值对的键
map与切片的结合
当我们想在切片里面放一些列用户的信息,这时我们可以顶一个元素为map的切片
|
|
|
|
map类型的排序
key升序排序
遍历key放在切片里面,对于切片进行排序,然后再输出
|
|
Go 运算符
golang
++ – 只能单独使用且只能写在变量后面
也就是
var a = 10
a = a++ //错误
a++ //正确


Go 流程控制
条件判断
go的条件判断语句和其他语言的不同点在于不需要再if后面加(), 现在很多语言都不需要了比如Swift if的{}不能省略
{左括号必须紧挨着if的条件判断或者else
循环语句
for
|
|
同样的go语言中的for也不需要写()
|
|
对于go来说没有while语句 可以使用for无限循环来代替
for range 键值循环
|
|
switch case
|
|
go语言的switch case如上所示,和很多比较新的语言一样,go语言中的switch case 不需要在每个case中单独的添加break, 每个语句执行会自动的break,如果想要执行穿透操作需要增加
fallthrough关键字
fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的
|
|
可以在switch case判断条件上写表达式
|
|
switch case 多个分支
|
|
可以在switch case 中的case语句中添加表达式这时就不需要再switch语句后面再判断变量
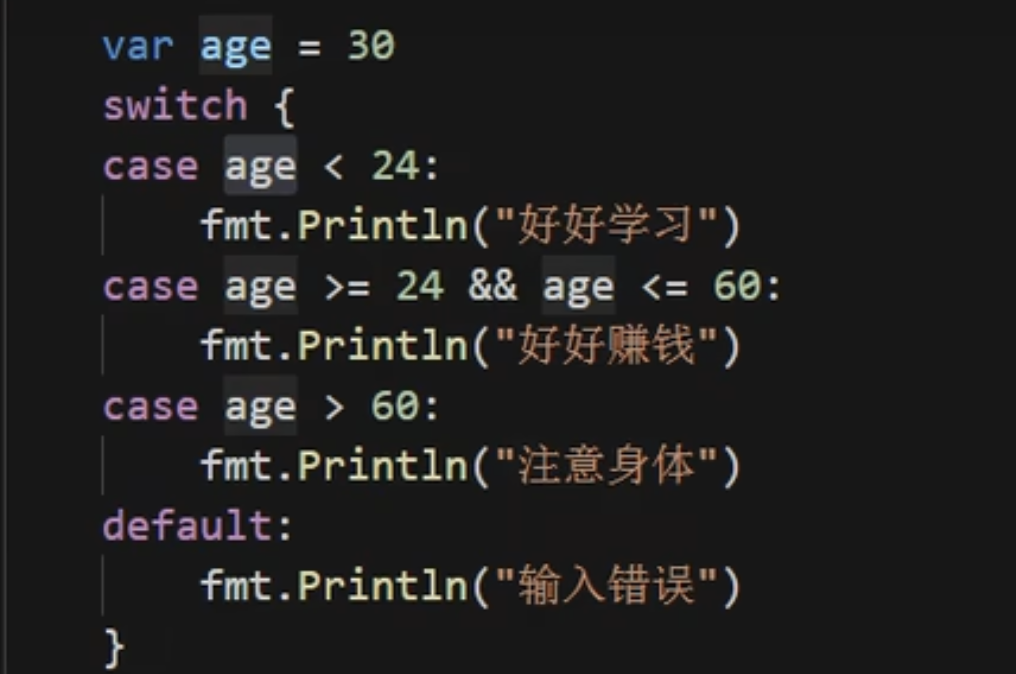
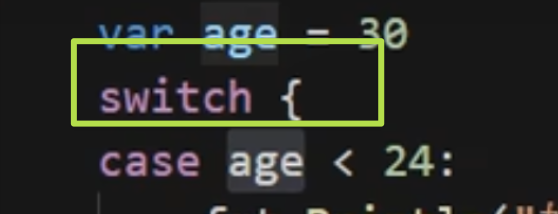
注意看switch 后面并没有跟任何的判断,这是因为在case中添加了判断条件
continue goto break
break
go语言中break语句用于以下几个方面:
- 用于循环语句中跳出循环,并开始执行循环之后的语句
- break在switch中执行一条case后跳出语句的作用
- 在多重循环中,可以用标号label标出想break的循环
label跳出多层循环
|
|
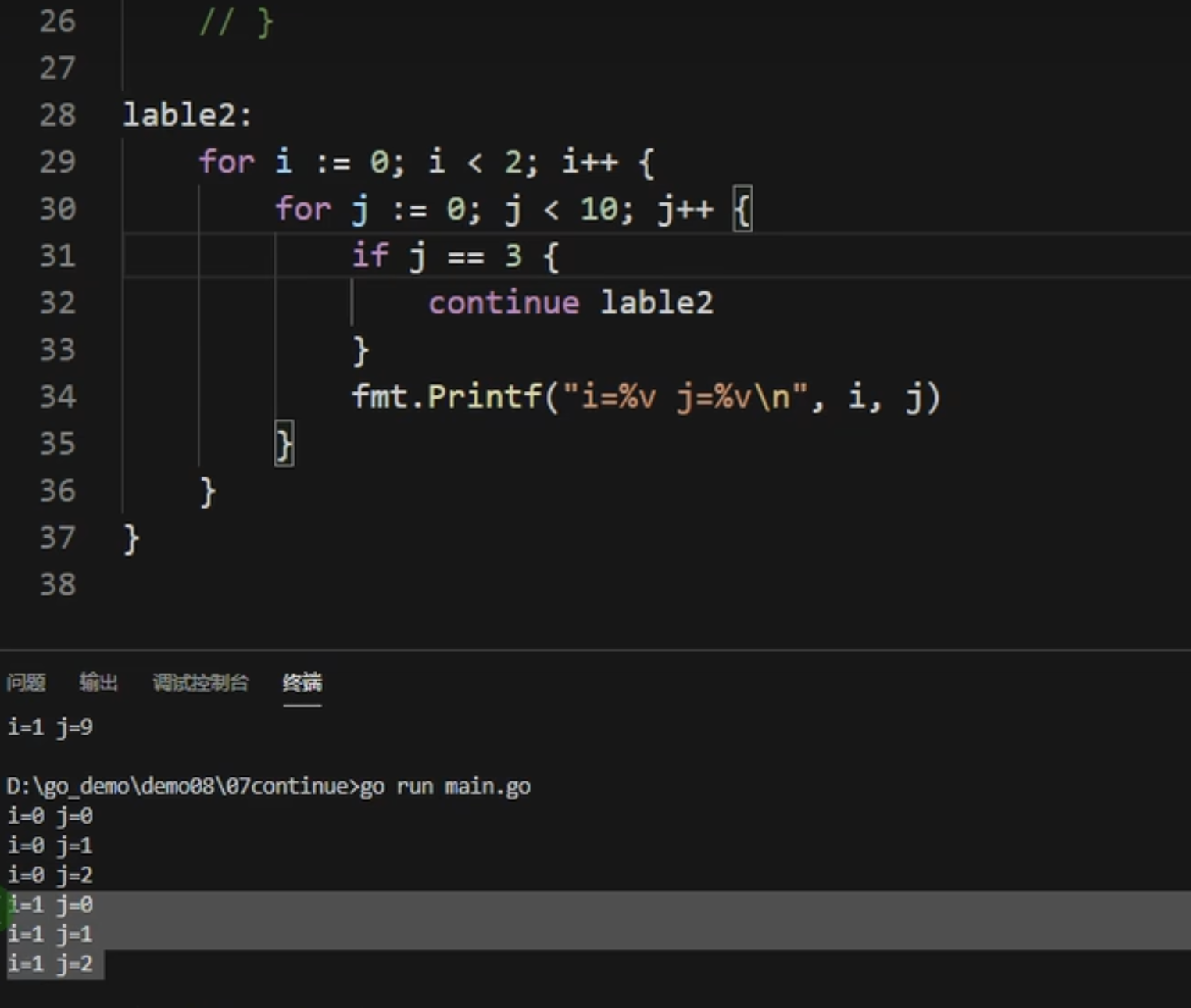
continue
跳过本次循环,但不跳过整体的循环,在continue语句后使用标签时,表示开始标签对应的循环
goto
goto 语句通过标签进行代码间的无条件跳转,goto语句可以快速跳出循环,避免循环重复
|
|